
Do you want to know how we change everything?
Schedule a call and we can show you how to boost your business.
 Siegfried Eckstedt
Siegfried Eckstedt
Let’s be fair. In this time of rapid innovation and the need for expert knowledge, it’s a tough call to be a master in all disciplines. Be it algorithm designs, project management, product design, you name it. It’s truly hard to span an umbrella to cover it all and still make it simple to follow through and produce effective results. Here is what I’d do: Blend Data Science into Design Thinking.
Design Thinking is a repeatable and scalable process for innovation. It is meant for designing products in a human-centered way. Typically, the Design Thinking flow starts within the problem space where one seeks to understand and frame the user’s perspective of the problem. With a well-defined problem statement, Design Thinkers brainstorm on how to solve it before the flow continues into the solution space. In that space, it’s all about prototyping and playing back the output to the user to receive feedback.
In Data Science, typically algorithms are trained to iteratively learn from data. This process is called Machine Learning and allows machines to find insights with or without explicit instruction where to look for the same. A project for applying Machine Learning typically starts with a problem definition, some provided data and a manual solution. After a exploratory data analysis, a Data Scientist would start to prepare the data so that it can be used for a selected algorithm to work on it. Based on the evaluation of results, the algorithm can be tuned.
To recap, Design Thinking is a human-centered process that focuses on the problem of users and can be applied to solve any fuzzy problem. Data Science is a data-centered discipline that is home to any domain (or problem space) and uses methods such as Machine Learning to solve decision-making tasks carried out by a computer.
Now that we understand that the one has it’s strength in the problem space and the other in the solution space, let’s bring the two together. The diagram below provides an overview of a process that flows through five stages allowing for iterations and repetition.
Prior to getting started into the journey, you should prepare your environment for working boldly. The Setup is centered around picking up an opportunity, assemble the crew and calling out the direction where to go.
A good opportunity might be a process that consists of small, repetitive tasks that are not too complicated for a human to do once but tough to repeat at high volume and high precision. There maybe an experienced / specialized person doing the job manually.
And that is the start of most of our use cases. Too often we expect humans to work like assembly line robots. And we do not create systems to assist the humans so that they can unfold their creative and social capacities.
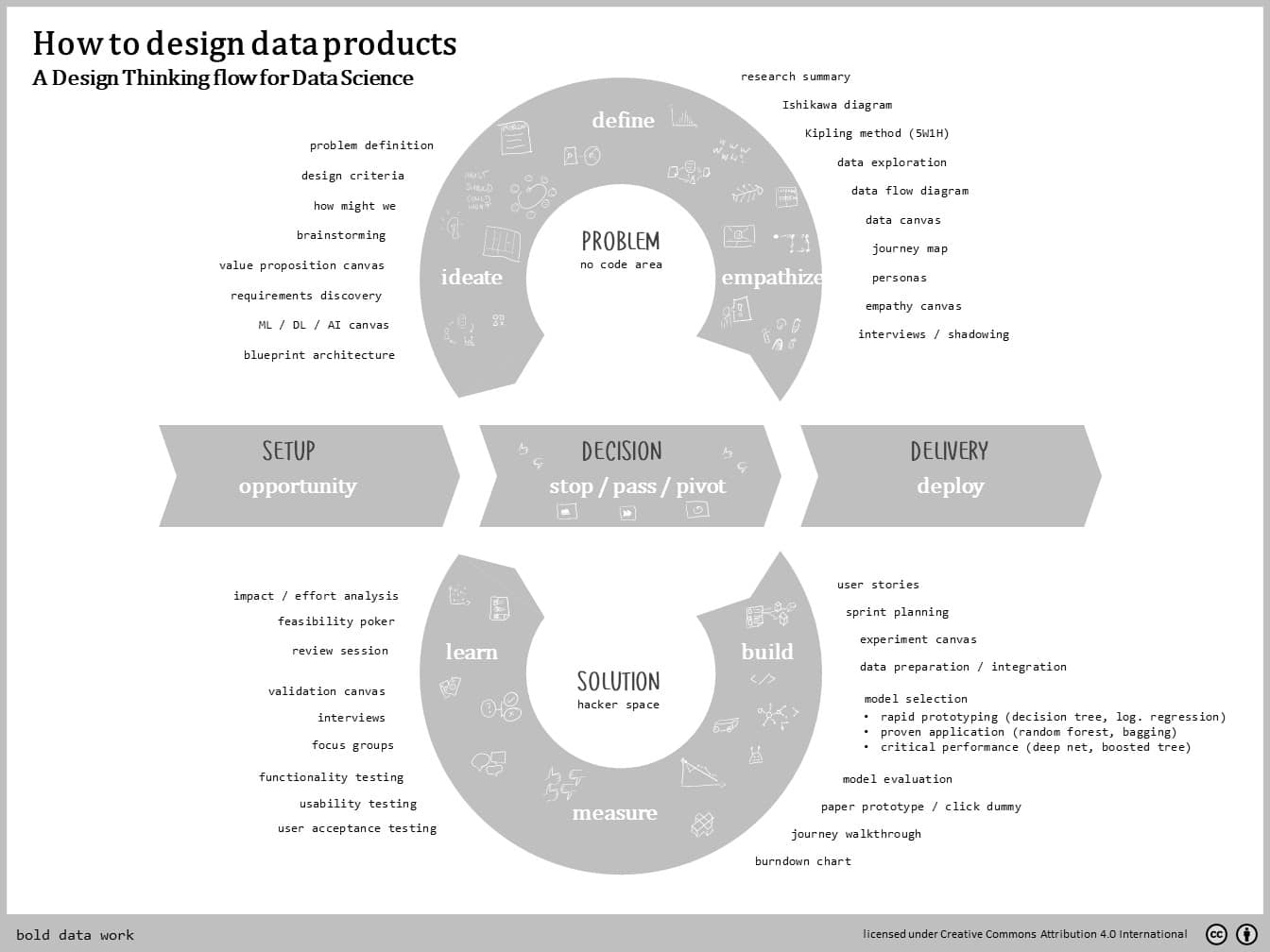
Once the team is together and has a clear direction what opportunity or challenge to pursue, you may emerge into the Problem Space. Hold your keyboards still though – this is a non-coding area.
First, one tries to zoom out and discover the full complexity and explore depth of the challenge at hand. In an effort to empathize with the user, you can hold interviews with customers, business units and teams. You can also look into some data begin to understand the flow of information and decision-making.
As you want to bring your observations into structure, you define the problem. This might seam odd because you’d assume to know the problem. Yet, practice shows that a thorough discovery may bring to light new insights that are often reason to redefine or refine the initial understanding of the problem.
So, how might we turn this into knowledge into a new product? Let’s ideate and envision a new future. In this step, you can run crazy and be truly creative. Tools such as value proposition canvases can help to structure crazy ideas into abstract product prototypes. For data-centered work, you may use a canvases with similar themes, e.g. ML / DL canvas.
Schedule a call and we can show you how to boost your business.
I know, it’s a tough call. But you have to choose. This step is a gate to filter out unpromising options and align the team on what to go for next. Actually, this step may be placed at any start, respectively end of a space / loop. It ensures that you are not wasting your time and take decisions.
Because, you should be be hard on your project and rather stop it sooner than later. Get your team together and pessimistically ask yourselves why this might fail and only keep going once all (technical) objections are met with a reasonable clue.
If the team is happy with the project, give the project a go and let it pass to the subsequent stage. This decision should not be taking lightly. Ask yourselves whether you are really still fulfilling against the aspired vision.
If you want to abandon the previous efforts to make a concerted effort towards a new option or idea, pivotthe process. Lessons may be learned from the old project, and parts may be salvaged and re-purposed.
Congratulations, you have arrived in the hacker space. Finally, we can start hammering our fingers on the keyboards to produce ML code.
Before you start building any system, invest a little time into planning out the sprints and translate the prototypes into a backlog of user stories. Get your ML model up and running – which includes selecting and transforming data and selecting an algorithm. For fast prototyping, keep things simple and just try your luck with a log. regression or a decision tree. Also, consider complementing your prototype by a click dummy.
What works, what does not? Let’s evaluate the performance of your prototype and run tests. Sure, we want to evaluate the performance of the ML model that we trained – for instance with test data or with live testing. But, also think about running the user through the experience and get the feedback. We don’t want to get too nerdy too soon, right?
Because we may miss out some learning. With the feedback of the users, you may refine and tune your algorithm to perform better and create a more integrated as well as pleasant experience. You should seek to understand what features had the most impact on the perceived value of your product.
To pivot or to scale up in delivery? The latter will take us back into the real world of operations. At the end of our sprints in the Solution Space, we have created a Minimum Viable Product – a product just good enough to be making money with our target customers.
To deploy the product is not only equal to making it a ship-able (and therefore durable) product. It also includes to convert the organisational setup from project to production-oriented teams, i.e. adopting structure, processes and culture.
Wow, that was a quick run through the flow. As I’ve only had a brief talk about each space and the referring steps, I would want to soon publish more on how to make some single steps work.
In the meantime, I want to hear back from you: How do you come up with new and innovative work in your Data Science projects?
The diagram is under CC license where you are free to share, copy and redistribute the material in any medium or format. If you can make sense of it, you can for sure adapt, remix, transform, and build upon the material.
Find all material on my GitHub and please help to improve this post there. Thank you for your contribution.
Schedule a call and we can show you how we can boost your business.
This website uses cookies to ensure you get the best experience.
Many subscribers already enjoy our premium stuff. Subscribe now.

